


Though advancements to technology are constantly evolving, it is clear incidents that can affect either minor organizations or large areas of the world, such as internet outages, can still find its way around those advancements and put a halt to production. What may not be clear, however, is the behind-the-scenes of those incidents. Is the organization aware of this issue? What are they doing to fix the problem, and when will it be resolved? Read below to gain insight on the 7 steps Atlassian uses in its transparent incident response strategy.
1. Detect: Those within your organization can be made aware of incidents in several ways other than simply discovering them, such as monitoring or customer reports. In any form of an incident being found, it is important to log a ticket for it. Atlassian members can then check if an incident is in progress. The five fields to fill in to obtain the most information about each incident are: summary, description, severity, faulty service, and affected products.
2. Implement communication channels: Open communications are essential in being considered in order to address the incident quickly. Once the ticket is created, the issue evolves to the fixing stage and is assigned to an incident manager. That designated member then prepares communication channels to establish and narrow a focused communication strategy, which typically includes a chat room, a video chat, and a Confluence page.
Sending follow-up communications wraps up the communication strategy for resolving an incident. Follow-ups keep both customers and staff in the loop of the incident's progress and develops a stronger trust with the organization. It is likely information on the incident will be little to none in the beginning, but making those involved aware from the start will only help them follow along as the incident progresses. An example of a strong follow-up message will consist of a small summary of the incident’s current state, with up to four bullet points on where it stands and what the next steps look like, and a date representing when another follow-up message is planned to be sent out.
3. Assess and apply severity: After the communication channels are implemented, the severity of the incident is assessed to decide what response level meets the level of severity. Some key focus points debated to determine that level are whether the impact of the incident is internal or external to the customer, how many customers are affected by the incident, and when the incident started.
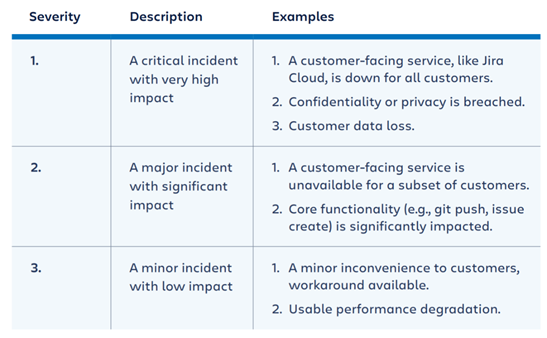
There are three severity levels among the one that will be assigned to the incident: critical incident with very high impact, major incident with significant impact, and a minor incident with low impact (see the image below for examples of each). The establishment of the incident’s impact is then followed by confirmation of the severity.
4. Communicate to customers: Sending initial communications on the incident is the next focus, as communicating both internally and externally will focus the incident response in one place and prevent avoidable confusion. Communicating with the customer that the organization is aware of a problem and is taking action to resolve it is just as important as communicating with the team about incident status and any new incidents because each action taken helps to build trust with both sides.
5. Escalate: This stage in the incident response process describes where more teams may need to get involved in resolving an incident than just the first responders. Opsgenie, a page rostering and alerting tool, allows teams to build lists of team members that can be contacted in an instance of an emergency. Having a list of reliable individuals to contact in certain dire situations is important because the alternative of having one specific individual can result in failure to resolve the issue, due to several circumstances of potentially being unavailable.
6. Delegate and iterate: When a member from one of those lists in the escalation stage is contacted, the role is delegated to that member. Again, communication is a major focus here, as the member will need an understanding of the incident and the role at hand in order to work quickly and effectively. The incident roles Atlassian uses are: the incident manager, the tech lead, and the communications manager.
The incident manager has overall responsibility and authority regarding the incident and will need to take necessary action to resolve the incident. The tech lead develops theories on what is broken and the reason why and decides and executes changes that need to be made to resolve the incident. Finally, the communications manager writes and delivers internal and external communications on the incident.
This stage also represents the iteration of the incident response process. It begins with observing what is happening and communicating observations with others, developing possible reasons for the occurrence of the incident, performing experiments that determine whether those reasons are the true causes, and repeating. This cycle is designed to be followed for many incident response scenarios.
7. Resolve: The resolve stage represents the end of the incident, where the current or imminent business impact is over. Any cleanup tasks are then performed and can be tracked to the main issue. The last round of internal and external communications is sent, explaining through a quick recap the impact and duration of the incident in addition to the number of support cases received.
In times of technical challenges such as incidents, transparency, and communication are vital in effectively overcoming those times. From detecting the incident immediately to communicating with the necessary team members to assist in the resolving process, Atlassian's incident management strategy enforces strong communication along every step to build trust with organizations affected by the incident.
At E7 we offer Journey to JSM packages which are designed to get your team into JSM with all the guesswork removed. Our out-of-the-box packages include strategic guidance, design workshops, assessments and recommendations, implementation, and training. More than a proof of concept, you'll have our expert analysis, scorecards to measure continued success, and a fully realized service management solution!
Stop wasting valuable resources with your service management systems and start your Journey to JSM today with E7 Solutions.





.png?width=300&height=115&name=New%20Project%20(1).png "Atlassian Platinum Solutions Partner")

